Runs on your own hardware
The native chat client for local models.
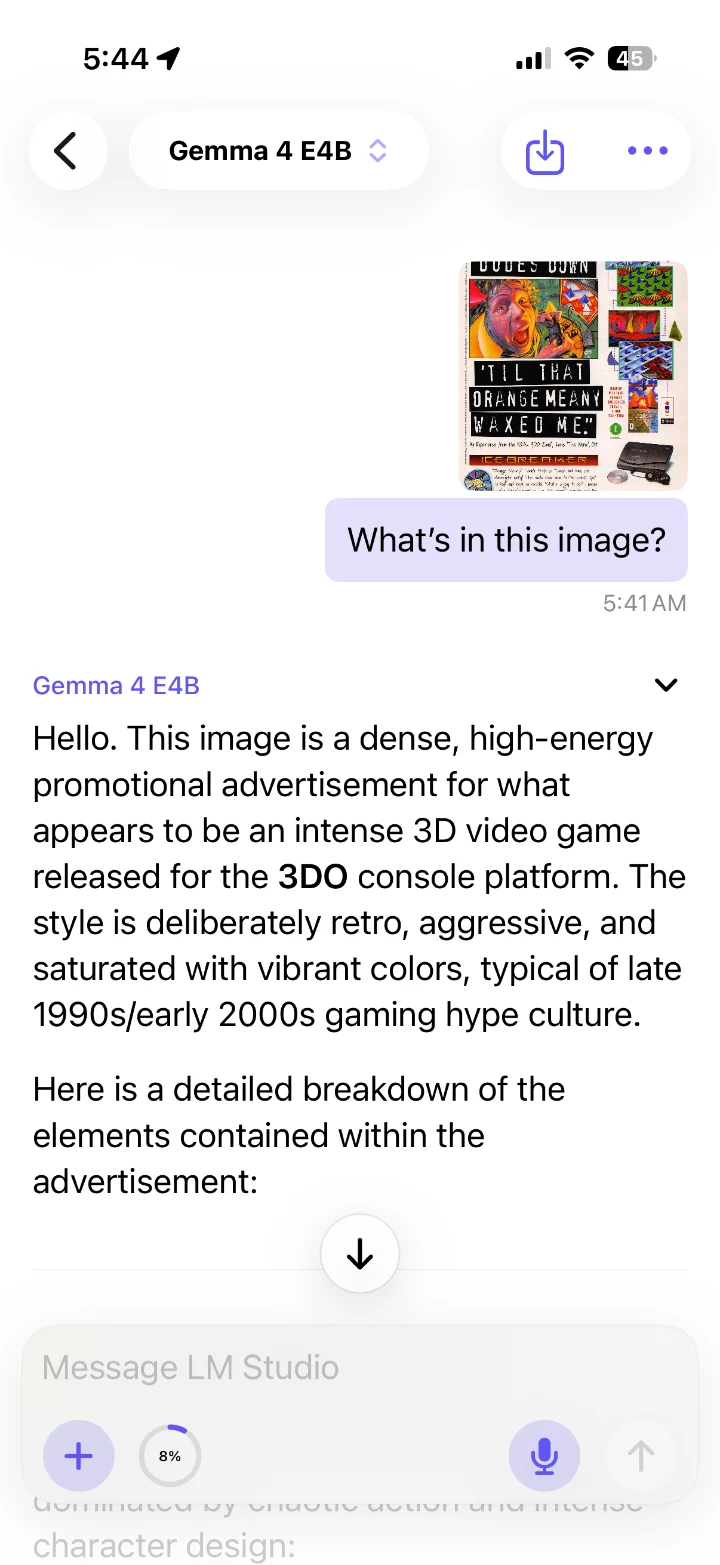
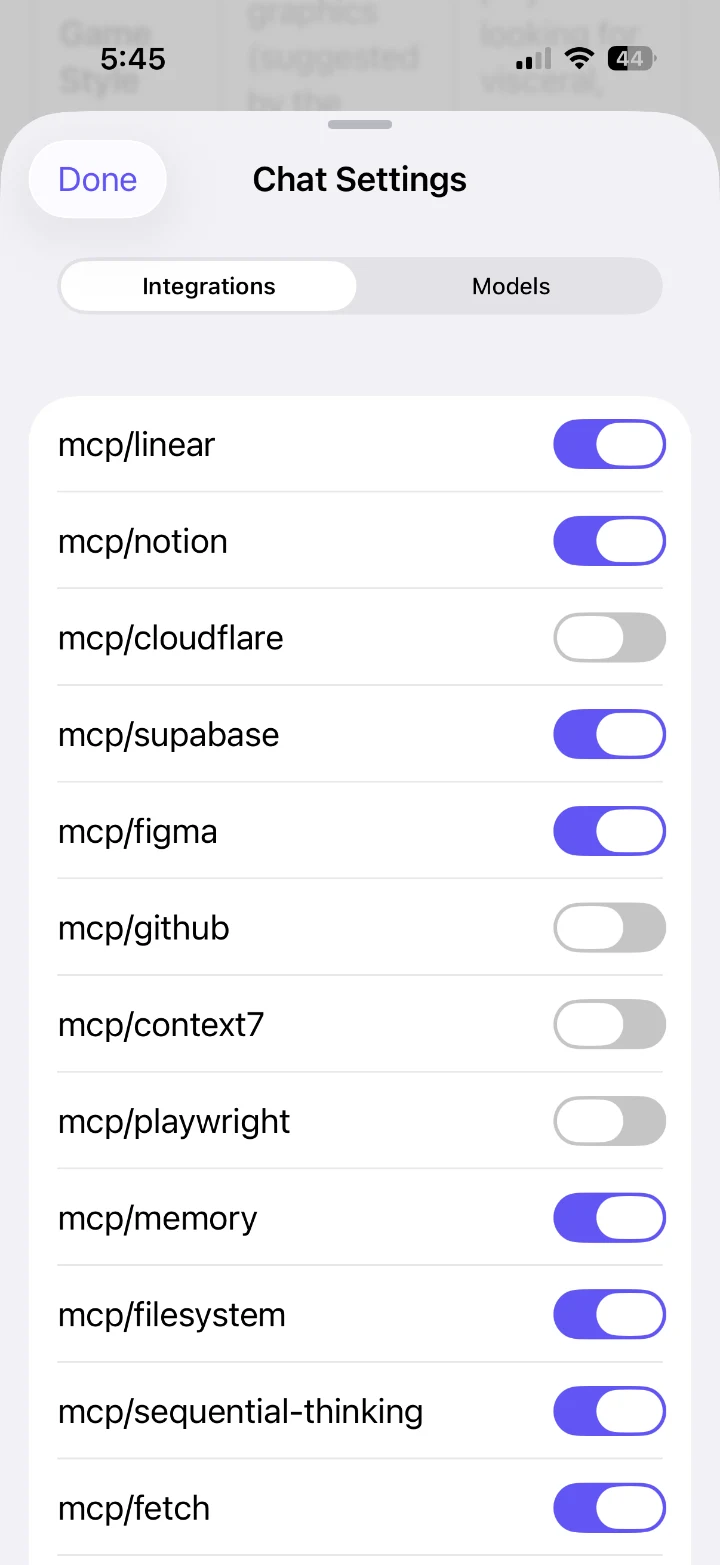
LLMster connects straight to your LM Studio server and streams chat, reasoning, tool calls and vision — in a fast, private app that feels like it shipped with iOS.
No cloud, no account. Your conversations never leave your network.
Chats
Folders
AI Research6
Music Production3
Stories2
Recents
5:46 AM
5:41 AM
5:39 AM
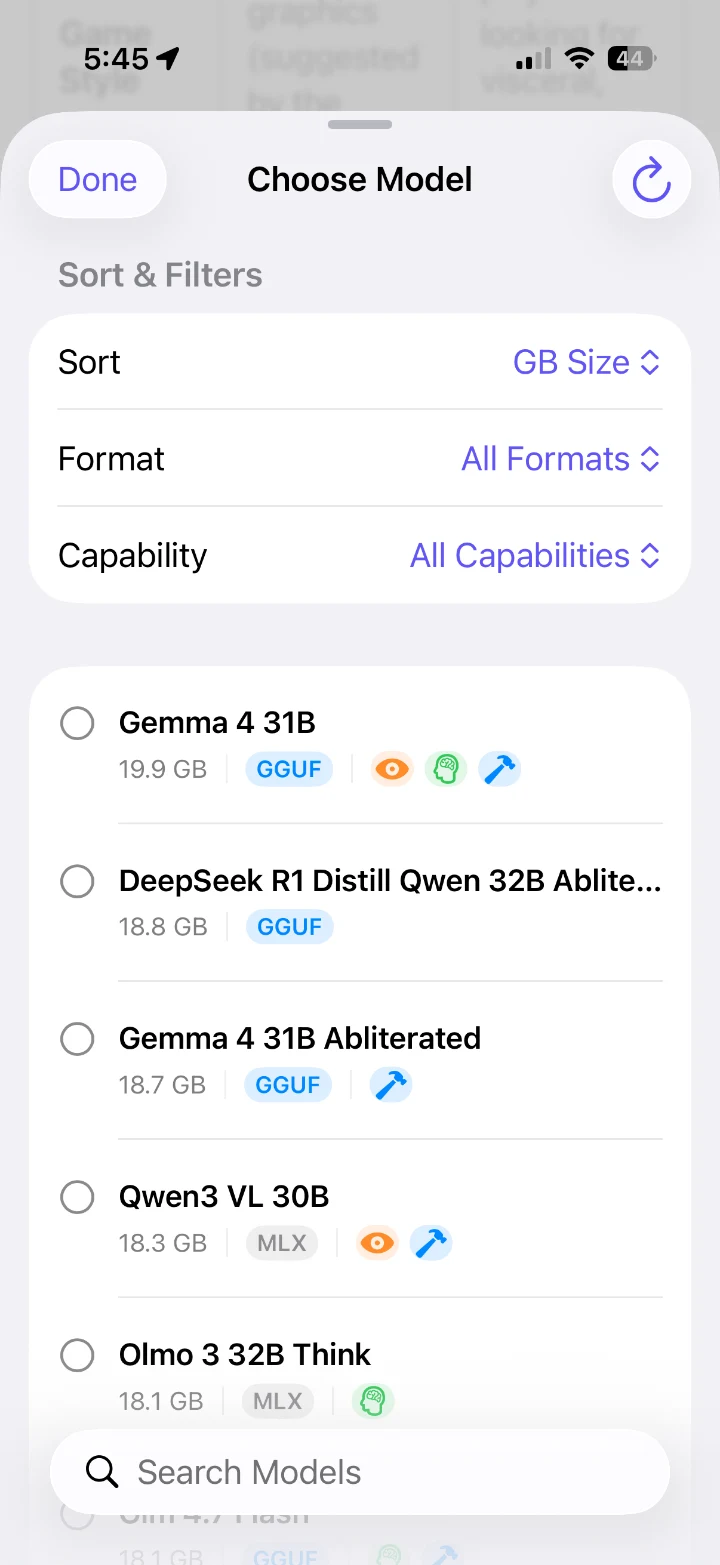
Runs the open models you already love
Works with LM Studio any GGUF or MLX model